前言
说是优化,其实跟多是对以前一些概念的巩固,毕竟实践还是在理论牢靠的基础上进行的。所以这里我们先看看我们常用的一些关联查询方式。
JOIN链接
- 应用形式
- 内连接
- 左连接
- 右连接
- 查询左表独有数据
- 查询右表独有数据
- 全连接
- 查询左右表各自的独有的数据
创建表数据
1 | -- 部门表 |
2 | DROP TABLE IF EXISTS `department`; |
3 | CREATE TABLE `department`( |
4 | `id` int(11) NOT NULL AUTO_INCREMENT, |
5 | `deptName` varchar(30) DEFAULT NULL, |
6 | `address` varchar(40) DEFAULT NULL, |
7 | PRIMARY KEY(`id`) |
8 | ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; |
9 | |
10 | INSERT INTO `department` VALUES ('1', '研发部(RD)', '2层'); |
11 | INSERT INTO `department` VALUES ('2', '人事部(HR)', '3层'); |
12 | INSERT INTO `department` VALUES ('3', '市场部(MK)', '4层'); |
13 | INSERT INTO `department` VALUES ('4', '后请部(MIS)', '5层'); |
14 | INSERT INTO `department` VALUES ('5', '财务部(FD)', '6层'); |
15 | |
16 | -- 员工表 |
17 | DROP TABLE IF EXISTS `employee`; |
18 | CREATE TABLE `employee` ( |
19 | `id` int(11) NOT NULL AUTO_INCREMENT, |
20 | `name` varchar(20) DEFAULT NULL, |
21 | `dep_id` int(11) DEFAULT NULL, |
22 | `age` int(11) DEFAULT NULL, |
23 | `salary` decimal(10, 2) DEFAULT NULL, |
24 | `cus_id` int(11) DEFAULT NULL, |
25 | PRIMARY KEY(`id`) |
26 | ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; |
27 | |
28 | INSERT INTO `employee` VALUES ('1', '鲁班', '1', '10', '1000.00', '1'); |
29 | INSERT INTO `employee` VALUES ('2', '后羿', '1', '20', '2000.00', '1'); |
30 | INSERT INTO `employee` VALUES ('3', '孙尚香', '1', '20', '2500.00', '1'); |
31 | INSERT INTO `employee` VALUES ('4', '凯', '4', '20', '3000.00', '1'); |
32 | INSERT INTO `employee` VALUES ('5', '典韦', '4', '40', '3500.00', '2'); |
33 | INSERT INTO `employee` VALUES ('6', '貂蝉', '6', '20', '5000.00', '1'); |
34 | INSERT INTO `employee` VALUES ('7', '孙膑', '6', '10', '5000.00', '1'); |
35 | INSERT INTO `employee` VALUES ('8', '蔡文姬', '30', '35', '4000.00', '1'); |
内连接
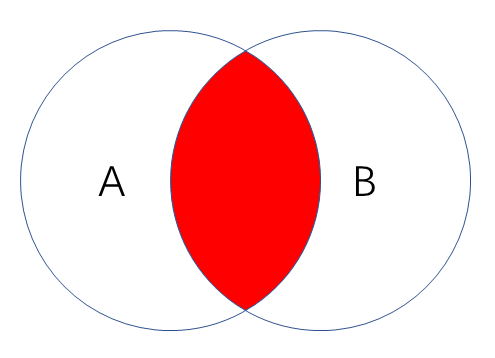
- 作用:查询两张表的共有部分
- 语句:SELECT field FROM tableA INNER JOIN tableB on A.key = B.key
1 | SELECT * FROM employee e INNER JOIN department d ON e.dep_id = d.id; |
左连接
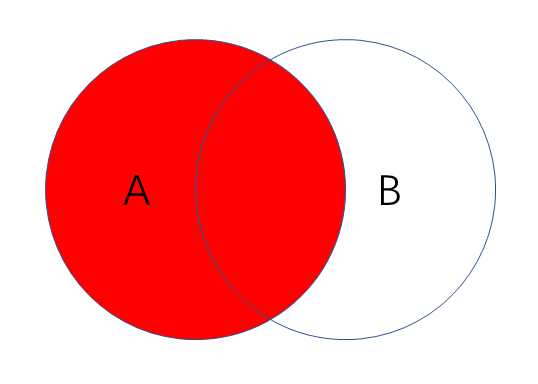
- 作用:把左边表的内容全部查出,右边表只查出满足条件的记录,A和B的共有再加上A的独有
- 语句:SELECT field FROM tableA LEFT JOIN tableB on A.key = B.key
1 | SELECT * FROM employee e LEFT JOIN department d ON e.dep_id = d.id; |
右连接
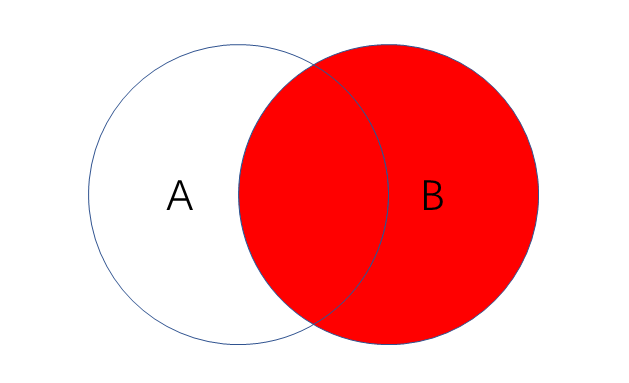
- 作用:把右边表的内容全部查出,左边表只查出满足条件的记录,A和B的共有再加上B的独有
- 语句:SELECT field FROM tableA RIGHT JOIN tableB on A.key = B.key
1 | SELECT * FROM employee e RIGHT JOIN department d on e.dep_id = d.id; |
查询左表独有数据——左连接基础上加上WHERE条件
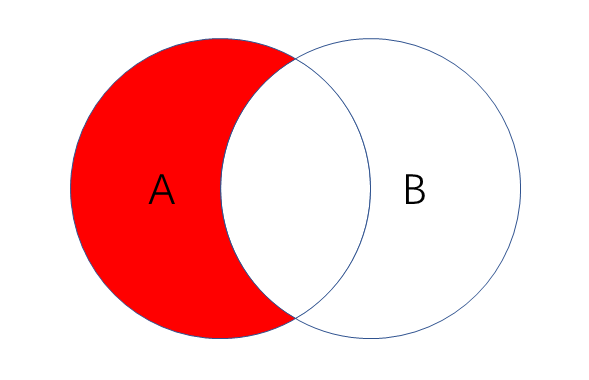
- 作用:获取左表数据,排除掉左表中的右表数据,
1 | SELECT * FROM employee e LEFT JOIN department d ON e.dep_id = d.id WHERE d.id is null; |
查询右表独有数据——有链接基础上加上WHERE条件
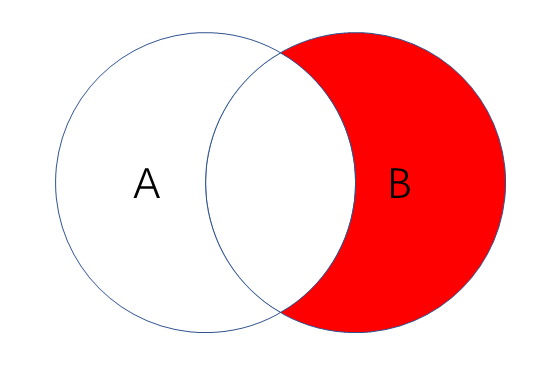
- 作用:获取右表数据,排除掉右表中的左表数据
1 | SELECT * FROM employee e RIGHT JOIN department d on e.dep_id = d.id WHERE e.dep_id is null; |
全连接
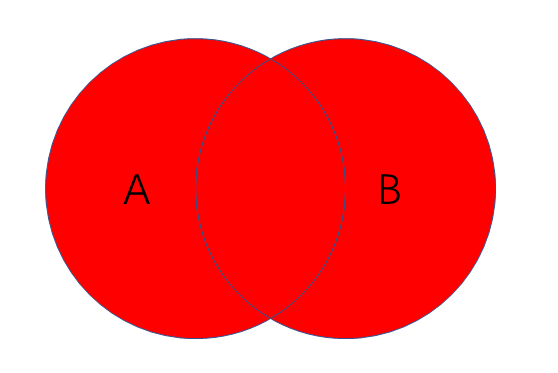
- 作用:查询两个表的全部信息
- 语句:SELECT field FROM employee e Full Outter Join department d ON e.dep_id = d.id;(MySQL不支持,Oracle可以,你说气不气)
1 | (SELECT * FROM employee e LEFT JOIN department d ON e.dep_id = d.id) |
2 | UNION |
3 | (SELECT * FROM employee e RIGHT JOIN department d ON e.dep_id = d.id) |
查询左右表各自的独有的数据
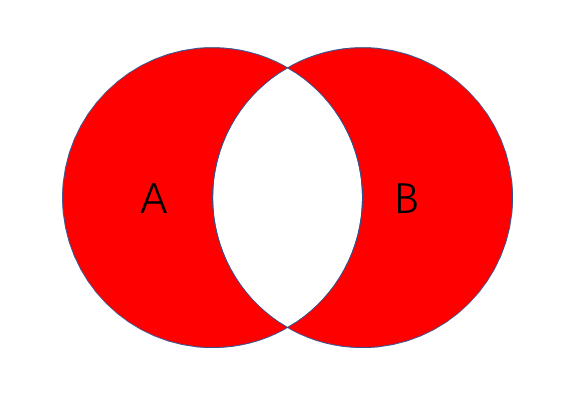
- 作用:左表独有数据和右表独有数据查出
1 | (SELECT * FROM employee e LEFT JOIN department d ON e.dep_id = d.id WHERE d.id is null) |
2 | UNION |
3 | (SELECT * FROM employee e RIGHT JOIN department d on e.dep_id = d.id WHERE e.dep_id is null) |